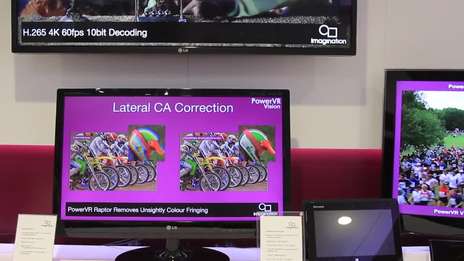
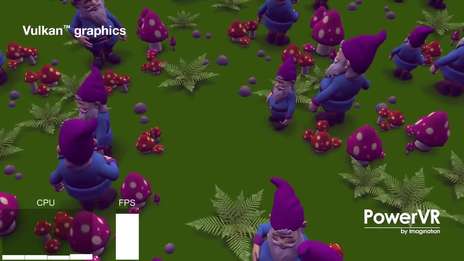
Imagination is a global technology leader whose products touch the lives of billions of people across the globe. We create and license market-leading processor solutions for graphics and vision & AI processing.
We’re all about supporting our next generation of talent. A career at Imagination means you are part of constant innovation; collaborating with the most brilliant minds to push the limits of technology.
![]() On the move?
On the move?
Find us on The Gradcracker App

Hardware Engineer
"I learn something new every day and my work goes into a product that reaches the hands of millions of people!"
Read more